Python: donner un vrai nom à vos process
( 28 Apr 2023 )
Quand on doit intervernir sur un serveur un peu inconnu
Il est 3h du mat, vous êtes encore mal réveillé (tu m'étonnes...), vous arrivez non sans mal à vous connecter sur le serveur de votre client malgrés les 36 niveaux de redirections mis en place.
La supervision est bien sûr aux abonnées absentes, et se limit à dire que l'application ne répond qu'une fois sur 2. Elle vous remonte également que le serveur a une grosse charge bie anormale.
Ok, vous avez déjà des pistes à explorer:
- la plateforme physique a un problème (genre RAID qui se dit que 3h du mat c'est un bon moment pour reconstruire un disque)
- soit c'est une VM qui se fait canibaliser son temps (ça arrive bien plus souvent qu'on pense, surtout chez les hébergeurs "cloud")
- soit une application sur le serveur est parti en vrille et bouffe toutes les ressources
Une fois sur la machine, premier réflexe:
df -h
(un grand classique celui là aussi...), mais non, l'espace disque est OK sur tous les volumes. Le client a tout mis sur /, simple, mais il aime le risque quand même.
On peut donc se concentrer sur un ralentissement. On lance donc un petit:
iostat -kx 5
Et là non, les disques ne sont pas solicités plus que ça, 20% max, ça va, on est large. On ne doit pas swapper non plus, on peux donc éliminer les problèmes de surconsommation RAM, dommage, c'est simple à régler au moins.
On passe donc côté CPU:
top
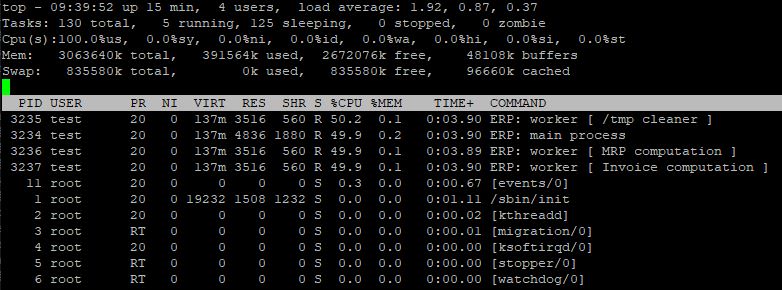
Petit tri sur M pour avoir le tri sur la mémoire, mais en effet, point de gros processus à l'horizon, c'est confirmé.
Par contre, le tri par CPU montre un processus Python à 100% de CPU. Sur une machine mono CPU, ceci explique pourquoi notre démon n'a plus de quoi répondre.
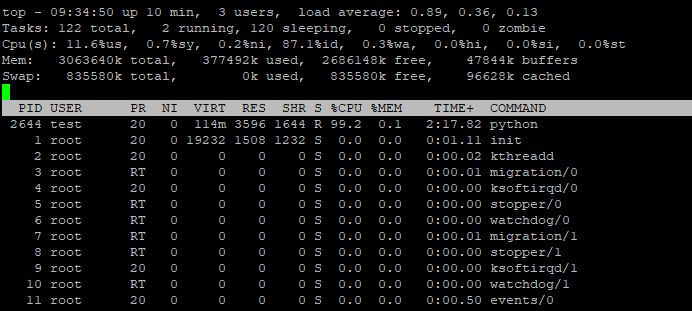

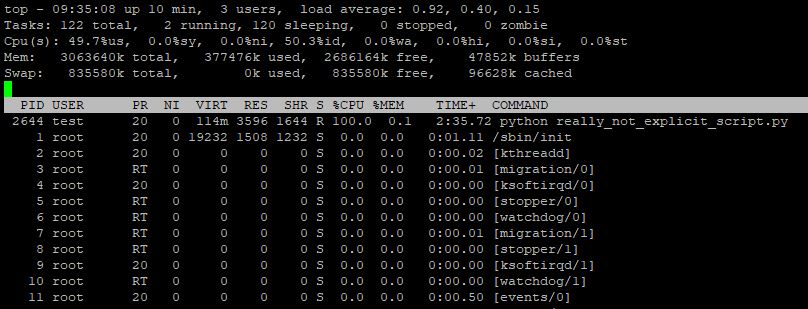
Par contre, juste python ça ne va pas nous aider. On met l'affichage des arguments pour voir le nom des scripts, et là encore ça ne nous aide pas.
Pas de responsable côté client sous la main pour savoir à quoi ils servent, et donc si on peut les tuer.
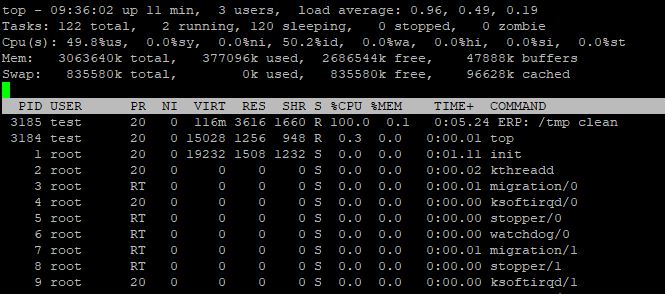
Si leur nom avait été plus clair, genre ERP: /tmp cleaner là ça aurait aidé, on sait qu'on aurait pu les tuer vu qu'on était large sur l'espace disque, ou au moins les nicer sans pitié.
Là bien obligé de les nicer, mais sans trop savoir si c'est grave ou pas.

Niveau novice: donner un nom à votre processus, c'est facile et rapide
Bref, si quand on développe un code, son rôle est clair et limpide (ou alors vou aurez du mal à le développer de toute manière ^^'), mais pensez que ceux qui vont repasser derrière après 5 ou 10ans vont également
avoir besoin de savoir ce que ça fait dans les grandes lignes.
Si les autres développeurs vont avoir droit aux commentaires, les administrateurs eux ne vont avoir qu'une et une seule chose pour se faire un avis rapidement: le nom du processus.
Et si vous ne faites rien, ça sera juste "python", on a déjà vu plus utile, il faut bien le reconnaitre.
C'est pourquoi je vous recommande de passer par un petit renommage de processus quand vous pouvez. La mise en place est triviale: c'est le paquet setproctitle. Trouvable sur Pypi.
Son appel est très simple également, et il s'occupe de toutes les petites bidouilles systèmes pour ça (car oui, c'est loin d'être si simple d'un point de vue système en fait, merci le poid de l'histoire du noyau Linux ici).
import setproctitle
setproctitle.setproctitle('ERP: /tmp cleaner')
Hop, finito. Même pas besoin d'être root pour le faire, vous pouvez y aller serein.

Niveau intermédiaire: donner un nom à vos processus fils également
Maintenant que vous mettez tous vos démons avec un nom de processus, les administrateurs vous aime bien, et vous autorise même à avoir des clés sur les serveurs (pas le compte root, faut pas déconner quand même).
Cas qui peut arriver si vous travaillez avec un énorme volume de données et Python, c'est l'utilisation de la libairie multiprocessing.
Une autre fois, j'expliquerai à quel point je la déteste, mais ce n'est pas le sujet aujourd'hui.
Multiprocessing permet de s'affranchir de LA plus grosse limite de Python à mon sens: il ne sait utiliser qu'un seul CPU (oui oui, même en async, il n'y a aucune magie) à l'heure actuelle.
Bon ça fait 10ans qu'on parle de faire sauter la limitation, donc je pense que ce sera encore le cas très longtemps après la sortie de cet article.

Multiprocessing permet de lancer des sous-processus, des workers, qui vont travailler sur une partie de vos données.
Si on met de côté tous ses bugs (lol, bon courage pour ne pas tomber dedans), c'est un moyen simple d'améliorer sensiblement ses performances.
Par contre, vos processus workers vont tous avoir le même nom, celui de votre processus principal. Pas très pratique:
- ni pour le développeur qui doit débugger dans un worker particulier
- encore moins pour l'administrateur qui se retrouve avec pleins de fois le même processus, mais chacun avec des rôles différents
^^'
Vous pouvez donc donner un nom au sous-processus. Il suffit de remettre un autre nom via setproctitle.
Astuce: pensez à garder une référence aux processus principal, si on n'affiche que le nom du processus fils, il faut encore être capable de savoir à quelle application il se réfère.
Niveau master: maintenir à jour sur le traitement actuel
Dernière astuce si vous en avez la possibilité, c'est de donner directement depuis le nom du processus l'avancement d'un traitement, ou son état de chargement par exemple.
C'est très raffiné, je trouve, et mine de rien bien pratique pour suivre un traitement directement avec un top.
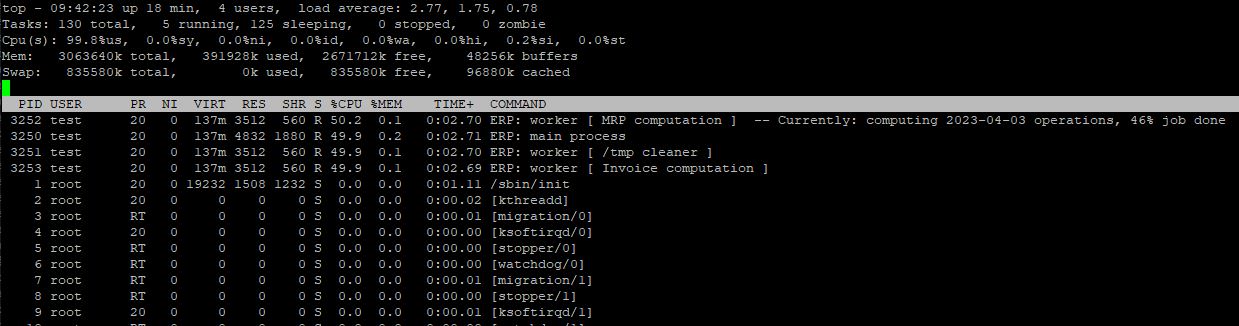

Petit détail, grande classe
Ce petit détail pour les développeurs est d'une grande aide pour l'administration.
Pour m'être retrouvé à revenir sur un programme qui n'avait pas le nommage des processus alors que j'y étais habitué, j'ai perdu beaucoup de temps lors des phases de debug. C'est quelque chose de tout bête, mais qui aide grandement quand on debug, et où le temps est précieux, genre à 3h du mat... :D

