Smart agent solution
( 20 Feb 2015 )Current pulling monitoring logic limits
Salut,
Aujourd'hui on va voir un sujet qui me trote dans la tête depuis quelques temps: la vision actuel de la supervision et ses limites. Depuis longtemps on a surtout utilisé le "pull", hérité des temps de Nagios.
Vous pouvez utiliser une méthode bourrine de supervision par SNMP, ou une méthode ingérable genre NRPE ou des checks plus avancés comme mes checks utilisant SSH.
Mais à la fin ce n'est qu'une question de protocole, la logique de récupération/pull reste la même.
C'est la raison pour laquelle Shinken est capable d'avoir autant de pollers: pour permettre d'avoir lancer autant de checks que vous avez besoin.
Ca marche. Même sur un très grand parc: si vous avez assez de pollers, vous pouvez superviser ce qui vous chante.
Mais ce n'est peut-être pas forcément la meilleure solution de faire.
Voici une illustration de deux de nos plus gros soucis en supervision:
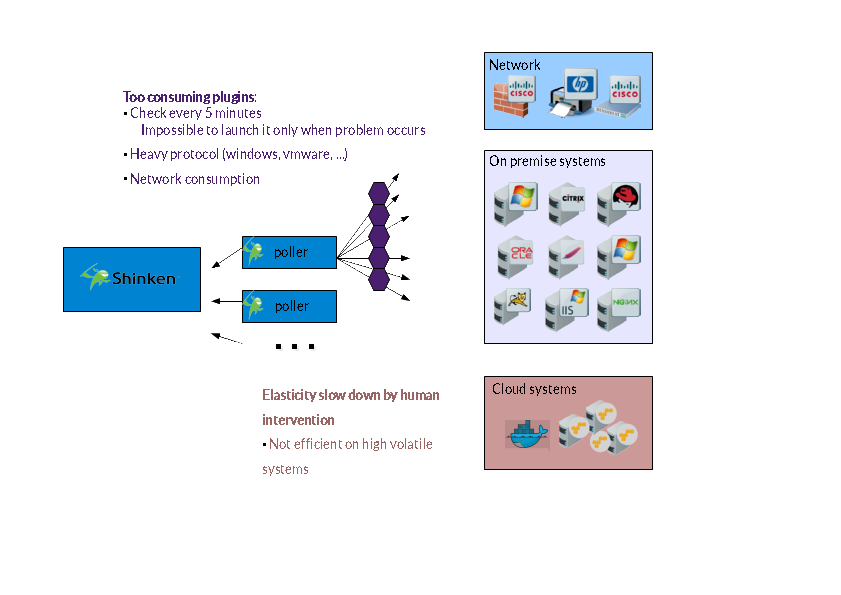
Consommation des sondes
Le premier problème est la consommation des sondes. Dans les installations les plus grandes de Shinken, j'ai déjà vu des pollers surchargés. En fait ce n'était pas le démon poller lui même mais les sondes qui consommaient tous les CPUs. Et tout particulièrement les sondes Windows et VMWare (à cause de leur protocoles SOAP & WMI qui sont très lourds). Bien sûr vpus pouvez rajouter des CPUs, mais on pourrait trouver une solution plus élégante, et moins couteuse à chauqe fois que vous rajoutez de nouveaux serveurs à superviser.
Cette consommation nous limite à rester dans le classique supervision toutes les 5 min (ou une minute) entre les vérifications. Certains vont superviser à 10s, mais seulement sur un scope réduit.
Après il faut dire que sans correction automatique, ça ne sert à rien de tomber en dessous de la minute, car même si vous avez l'alerte en 10s, le pauvre humain en face de son client mail mettra bien plus que la minute pour comprendre l'erreur, et commencer à intervenir sur le bon serveur ^^
Besoin pour plus d'élasticité
Le second problème est plus récent. Avec le cloud (Je mets dans le même paquet EC2, Openstack et docker ici) le besoin d'élasticité est devenu plus critique que les performances brutes. Vous voulez votre instance EC2 supervisée dès qu'elle est prête, pas 1h après ^^ Surtout qu'il y a des chances qu'elle n'existe plus dans 1h de toute manière...
Certains framework comme kubernetes peuvent aider, mais ça reste sacrément complexe, et une solution plus simple serait bénéfique pour le plus grand nombre.
Ma solution
Smart agent
Durant des années, la supervision sans agent était Reine. Par-ce que le pulling était acceptable d'un point de vue CPU, et que l'élasticité était une exception, pas la norme. Gérer une armée d'agent était un CAUCHEMARD car ils ne répondaient qu'à un serveur centralisé et ne tentaient pas d'être intelligent à la place de ce dernier (oui NRPE et tes clones, c'est bien de vous que je parle).
Mais un agent intelligent ce n'est pas juste lancer les sondes localement, et donc se limite à la partie supervision. Mais c'est également alléger la partie la plus coûteuse d'une solution de supervision: la gestion de configuration. Par exemple l'agent peux détecter de quel type est un serveur, ce qu'il y a dessus, et automatiquement assigner des checks (définis de manière centralisée), ainsi que des informations utiles pour les checks (pensez à l'ip publique par exemple). Un tel agent serait une véritable force pour une solution de supervision.
On booste les performances
Un tel agent lance les checks localement, et pour ne pas surcharger inutilement le serveur central, autant ne lui envoyer que les changement d'état. Avec une telle baisse de consommation de bande passante et ressource, il n'y a alors aucune pitié à descendre drastiquement les intervales de vérifications. 10s de base pour chaque check est alors la norme facilement accessible, plus l'exception.
L'élasticité maximum
Pour le problème de l'élasticité, quand l'agent démarre, il détecte son OS et les applications sur le serveur, et va se déclarer de lui même au serveur Central.
Fonctionnement de l'agent
Voici une vue d'ensemble d'un tel système:
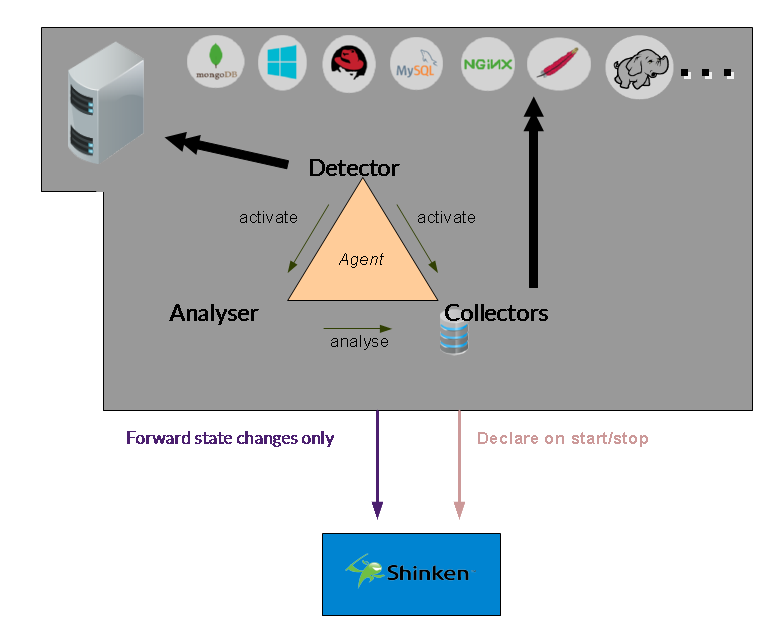
Avec 3 grandes parties:
- Les détectors détectent le type de serveur et les applications qui tournent dessus
- Les collectors vont récupérer des données brutes, du systèmes et des applications
- L'analyser lance les checks, et averti en cas de changement d'état
Le point principal est de décorréler la récupération des données, et la vérification. Ainsi, ils peuvent avoir facilement des rythmes totalement différents.
Gestion de configuration
La gestion de configuration locale des NRPE-like est un véritable enfer à gérer sur un grand parc. Voici pourquoi je réutilise la philosophie que j'ai mis dans Shinken Enterprise: ne pas définir manuellement, mais se baser sur un moteur de règles:
- redis est installé => c'est un serveur redis
- window fonctionne => on active la récolte windows et ses checks
- votre ip est dans le range EC2-East => on averti les bons administrateurs
- ...
Un jeu de même règle va donner des résultats différents suivants vos serveur, c'est bien plus simple à gérer que X configurations locales.
Finalement une solution efficace: vous mettez l'agent, la configuration est finie.
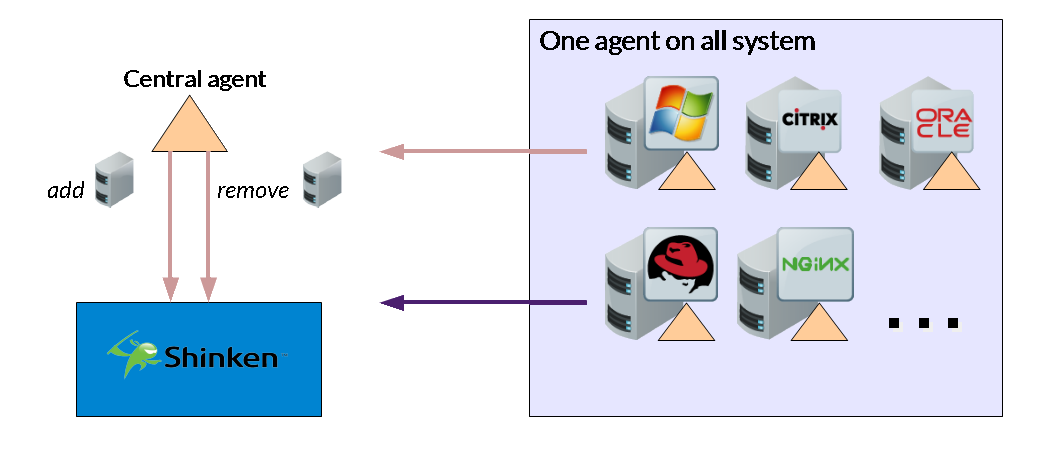
- Vous lancez un nouveau serveur? Il va être rajouté à Shinken en quelques secondes, déjà taggué (windows, iis par exemple)
- Ceci va alléger fortement le nombre de pollers dédiés aux serveurs, de quoi booster la précision sur les checks purement réseaux :)
- Supervision "Out of the box" avec les bons collectors et les bonnes règles ^^
Votre avis?
Bien sûr un agent ne peux pas tout résoudre, comme le pulling ne peux pas tout résoudre non plus. Il faut une allisance des deux pour avoir une solution complète et scalable.
C'est un POC en cours, juste pour proposer des idées. Je prends tous les retours sur tout cela (づ。◕‿‿◕。)づ
