Strace, l'outil de la dernière chance
( 31 Mar 2023 )Les applications ça plante, souvent (╥﹏╥)
Tout administrateur l'apprend assez vite à ses dépens: les applications ça plante, et ça plante souvent.
Point de magie à cela, elles sont de plus en plus complexes, avec de plus en plus de fonctionalités. De plus, vu qu'il faut les produire de plus en plus vite, on a recours à des frameworks tout faits qui rajoutent leur propre couche de complexité.
Et qui dit complexe, dit moins stable. Bien sûr, on peut rajouter des mécanismes de hautes disponibilités si l'application le permets, mais parfois ceci rajoute lui-même une grosse couche de complexité qui va avoir ses propres problèmes si elle n'est pas bien maitrisée.

Bref, ça va planter. Et d'un certain côté tant mieux, ça donne du travail à ceux qui font des outils de supervision ٩(^‿^)۶
Sans logs point de solution, ou presque
Quand ça va planter (et on a vu que ce n'est qu'une question de temps), les administrateurs n'ont pas un milliard de solutions. Nous ne sommes pas surhumains ou des magiciens, on va faire avec les erreurs que l'application donne, soit directement à l'écran, soit côté backend.
Peu importe qu'ils soient sous forme de logs locaux, centralisés, ou bien trace, ça revient grosso modo au même: l'application nous donne l'erreur comme elle le voit, avec son interprétation.
L'erreur peut être volumineuse (coucou Java et ses grosses stacks inparsables....), ou bien sommaire, mais elle donne quelque chose à se mettre sous la dent pour l'administrateur.
La suite va dépendre si l'erreur est assez claire. Un Failed to connect to srv-mysql port 3306: Connection refused va être assez
simple: votre serveur mysql est arrété (si c'était un firewall, on aurait plus un timeout, moins de chance d'avoir un refused du firewall).
L'admin sait où chercher, et va voir du côté de la base ce qui se passe. Là encore, les logs/traces vont être déterminants.
Bon là, c'est pour les cas un peu simples. Heureusement, d'expérience ça représente bien 90/95% des cas: on part rarement avec juste rien. Bon j'inclu aussi les cas où les utilisateurs arrivent avec "ça ne marche pas", sans autre détail, mais une petite prise de main à distance plus tard, soit l'utilisateur a découvert qu'en fait il faisait n'importe quoi (bien 1/4 des cas), soit on arrive à avoir le message où commencer à investiguer.
Les derniers 5%: l'enfer sur Terre
Ca se trouve, c'est pas si grave, un reboot et on repart
Bon vous me voyez venir, il reste les autres cas. Ceux où juste ça ne marche plus, mais sans message clair. Juste on lance, et rien ne se passe. Aucune erreur, juste: rien.
Bon là en général un admin avec un peu d'expérience va faire une première action en priorité numéro 1: il va prendre un café, car dans pas longtemps il risque de ne plus avoir le temps d'aller en prendre un \̅_̅/̷̚ʾ(•◡•)

Après la seconde étape va dépendre un peu de l'admin, de la récurrence du problème (déjà arrivé ou pas), et si l'application doit vraiment repartir MAINTENANT (en majuscule, à ne pas confondre avec le "maintenant" des chefs de projets qui est en fait un "dès que possible" mais déguisé).
Si le problème est récurrent, qu'on a jamais trouvé d'où ça vient, et qu'il faut vraiment que la production reparte, point de solution: on relance l'application et ses dépendances en totalités. Cette solution (aussi nommée "méthode Windows", allez savoir pourquoi... non je blague, tout le monde sait pourquoi) a le grand avantage de régler la quasi-totalité des problèmes. Bon par contre on ne sait pas d'où vient le problème à la source, mais on a au moins un contournement.
Je mets de côté le cas où c'est la première fois qu'on rencontre le problème, car dans ce cas on pars directement en analyse en ne touchant à rien pour ne pas empirer la situation.
On est mal ^^
Mais parfois, même le massive reboot ne suffit pas. Aucun message, logs ou trace ne nous aiguille vers la source du problème (qui peut venir de 3 stacks en dessous de l'application, sinon ce n'est pas drôle).
Dans ce cas, l'application ne nous aidant pas, il va falloir se passer d'elle et tenter de "deviner" ce qui ne lui plait pas. (Une autre solution est de balancer le problème chez les développeurs de l'application si vous les avez sous la main, mais si ça permet de calmer votre chef car le problème est ailleurs désormais, ça ne relance pas votre production pour autant ^^')
Ici, celui qui ne m'a jamais laissé tombé porte un nom: strace.

strace, quand le problème est entre l'application et l'OS
strace s'installe nativement sur votre système, c'est à portée d'un dnf/apt. Cette commande n'est en rien magique. Elle est même au final
assez simple dans son fonctionnement: elle va tracer les appels systèmes entre vos applications (qu'elles soient déjà lancées ou pas) et l'OS.
On va y voir tout ce qui se passe entre votre application et le système. Mais, le problème, c'est que quand je dis tout, c'est TOUT. Sa sortie est verbeuse, car
les applications font un MAX d'appels systèmes tout le temps, et principalement au lancement, là où en général vous avez des problèmes (╯︵╰,)
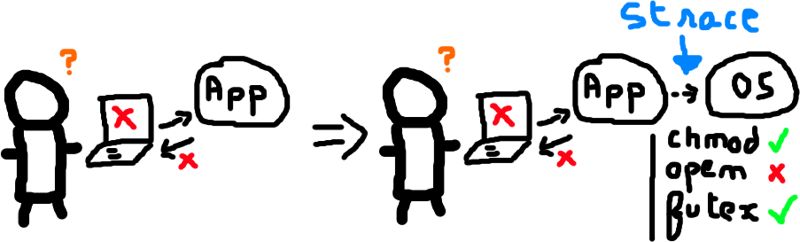
Le cas simple de strace est de lancer la commande avec par exemple:
strace ls -thor
On va avoir une sortie de la sorte:
$ strace ls -thor
execve("/usr/bin/ls", ["ls", "-thor"], 0x7fffbd60f428 /* 43 vars */) = 0
brk(NULL) = 0x1ca9000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f6578ed3000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=40994, ...}) = 0
mmap(NULL, 40994, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f6578ec8000
close(3) = 0
open("/lib64/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\220j\0\0\0\0\0\0"..., 832) = 832
...
openat(AT_FDCWD, ".", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 3
getdents(3, /* 84 entries */, 32768) = 3240

On voit l'appel au lancement du binaire. Puis après pas mal de chargement de fichiers et librairies et le listing du répertoire "."
Ce qui va nous intéresser le plus, ce sont les erreurs, du genre:
connect(4, {sa_family=AF_UNIX, sun_path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory)
nscd est un démon de cache qui peut ou pas exister sur la machine. Ici, c'est la négative. Est-ce un problème dans notre cas? Non, ce n'est qu'un cache. Et là vous voyez le problème: il y a les bonnes erreurs, et les mauvaises erreurs.
Ici malheureusement, il va falloir montrer les muscles, et apprendre un peu tous ces rouages de l'OS afin de les identifier, et les filtrer rapidement.
Prennons un vrai cas avec une erreur:
strace ls -thor /n-existe-pas
L'appel qui va nous intéresser va etre celui-ci:
lstat("/n-existe-pas", 0x1f84600) = -1 ENOENT (No such file or directory)
strace vous donne des données brutes, mais ça va rester à vous de faire le travail in-fine. Rien de magique.
Par contre, ce qui est intéressant, c'est que vous êtes quasi sûr que l'erreur est dedans. Juste qu'un simple ls génère 150 lignes, alors imaginez un lancement
d'un apache récalcitrant.
Ce que je vous recommande d'ailleurs pour son lancement:
- mettre la sortie dans un fichier (
-o) - tracer également les threads et autre processus fils (
-f) - ne pas limiter la taille des strings dans les arguments des appels, ça aide (
-s 999999)
Ceci nous donne donc:
strace -o /tmp/trace.txt -f -s 999999 ls -thor /n-existe-pas
Vu sa verbosité, c'est à utiliser en dernier recours, mais ça peut sauver des productions.
Le jour où strace a débloqué plus de 300 personnes, et calmé mon chef
Dans mon cas, en 2008 ou 2009, nous avions un GROS erp Oracle, avec plusieurs apaches intégrés (chacun sa version, sa gestion de log, etc, un véritable enfer à administrer avec
une surcouche xml d'Oracle qui n'aidait pas).
Et un jour en production, une partie de l'application ne démarrait plus. Rien dans les nombreux logs:
- espace disque ok
- pas de soucis réseaux
- dns OK également (flute, souvent un bon bouc émissaire)
- cluster Oracle OK
- reboot fait, mais n'a rien changé

Aucun des suspects habituels. Ça faisait déjà bien 3/4h que 300 utilisateurs attendaient leur ERP, dans une société de l'industrie, c'est long, TRES long.

Je sors donc mon copain strace, en désespoir de cause. Vu qu'il nous manquait un des démons apache, je me suis concentré sur ce dernier:
- j'ai trouvé son lancement sur un appel
execve, j'avais donc son PID - j'ai grep tout ce qui concenait de PID d'apache dans la sortie de
strace - j'ai vu un
open()sur un obscur log qui retournait en erreur (je n'ai plus le code d'erreur préci, mais ce n'était pas un succès ^^) - en allant voir le log, il faisait pile-poil 2Go. Pas un octet de plus ou de moins. Louche
- je regarde l'appel système en question, et en effet, il ne pouvait pas ouvrir de fichiers de plus de 2Go, il fallait passer sur un appel du genre
open64() - je clean le log avec un bon vieux
> fichier-log - ça redémarre enfin
♪┏(°.°)┛┗(°.°)┓┗(°.°)┛┏(°.°)┓ ♪

J'avais découvert strace peu de temps avant. Sans lui, on aurait du faire appel au support Oracle, et vu la qualité de leurs réponses à l'époque, la
production attendrait encore de redémarrer, nos 300 utilisateurs au chômage technique ლ(ಠ益ಠლ)
strace sur un processus qui tourne déjà
Un dernier cas où je trouve strace pratique, c'est pour aller s'accrocher sur un processus qui est bloqué. Par exemple:
strace -o /tmp/trace.txt -f -s 999999 -p PID
On pourra avoir par exemple un:
select(5, NULL, NULL, NULL, {tv_sec=0, tv_usec=50000} <unfinished ...>
- là on sait que le processus attend le filre descriptor
5 - on va voir qui est ce file descriptor
5dans le processus vials -thor /proc/PID/fd- et on trouve ainsi sur quelle socket/fichier il bloque
Pas le seul outil dans son domaine, mais réponds toujours présent
strace n'est pas le seul à opérer dans cette couche pour trouver les appels systèmes qui posent des problèmes. Un de ses sucesseurs est le fameux eBPF dont on parlera
peut-être un jour.
Ce dernier est un strace sous stéroïdes, qui ralenti beaucoup moins que strace, est capable de filtrage bien plus précis, etc. Mais le problème, c'est que ce n'est
pas encore d'une stabilité à toute épreuve, et que son API évolue beaucoup, donc on n'est pas forcément sûr que son "script" de debug va bien fonctionner sur
un ancien serveur par exemple (si tant est qu'il soit disponible, ce qui est loin d'être certain).
Nul doute qu'eBPF rendra obsolète strace un jour, mais ce dernier a encore l'avantage d'être toujours là, peu importe les situations ou les règles de sécurité.

La couche système que j'apprécie tout particulèrement
Comme vous avez pu le voir au fil de ce post, c'est une couche que j'apprécie énormément. Cette couche des appels systèmes révèle tous les petits détails croustillant sur les trucs et astuces du système, sur comment les différents blocs fonctionnent entre eux.
strace est justement un moyen de trouver des problèmes, mais également découvrir tous pleins de nouveaux mécanismes systèmes.
Quand je fais appel à strace, c'est
que j'ai un gros problème, mais une chose est sûre: même après quasi 20 ans à faire du Linux, je vais sûrement découvrir encore un ou deux trucs que je ne
connais pas encore.
Et rien que pour ça, je sais que je vais passer un bon moment ༼ つ ◕_◕ ༽つ

